
Post 43: Scaling laws and protein language models 💸
Published:
Today is Tuesday, Tuesday of “only China could have achieved this” 😬
Language models are the algorithms that make AIs like ChatGPT work. These algorithms learn multiple topics at once (medicine, architecture, etc.). For this to be possible, two aspects must be considered: the amount of data used in training and the number of neuronal connections (AKA the size of the model).
The capabilities of these models follow “scaling laws” which say that: as the size of the model increases, the AI learns topics better and new ones appear. As exemplified by the branches of a tree and their size. For example: by doubling the size of the model, the AI goes from knowing basic biology to knowing genetics. For this reason, there are increasingly larger AIs. But what would happen if proteins were used instead of text?
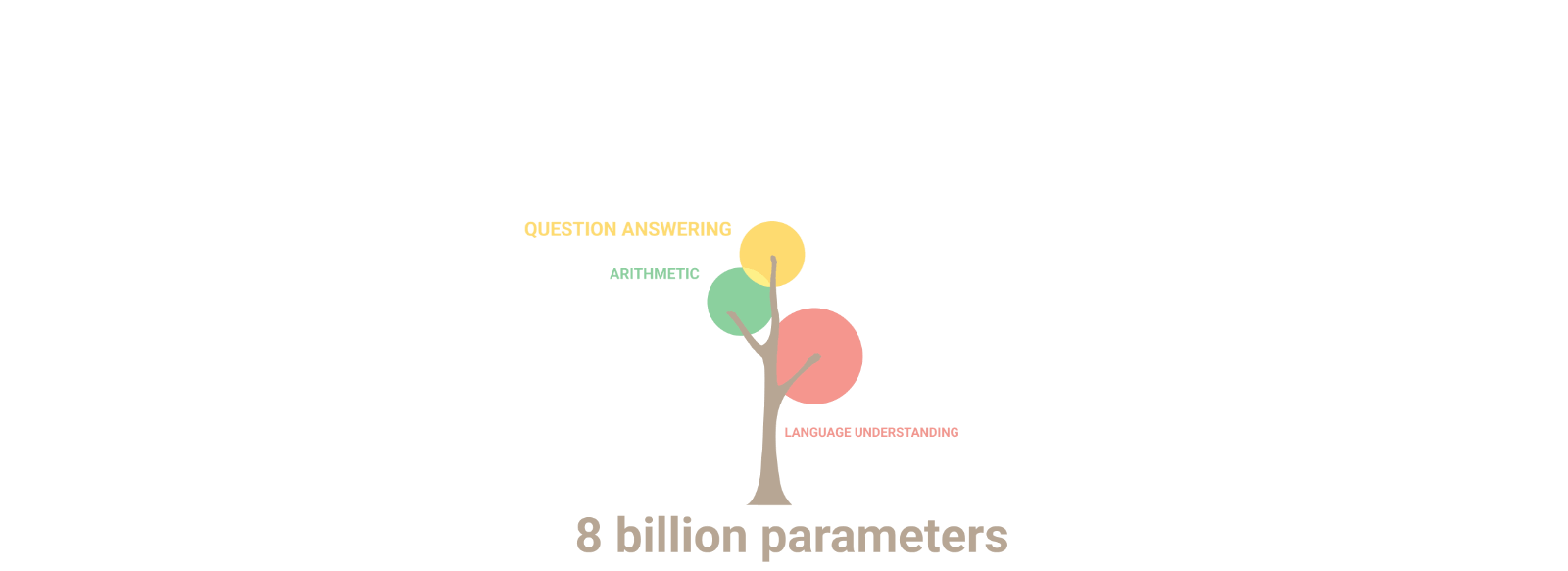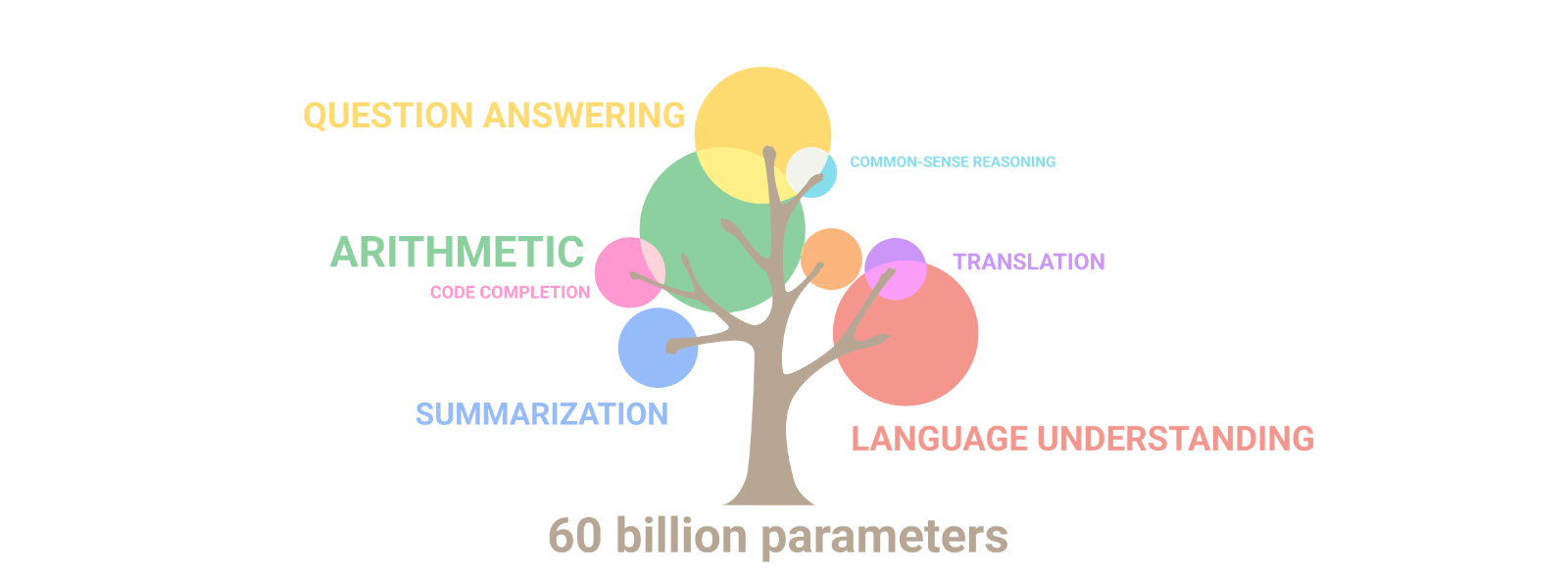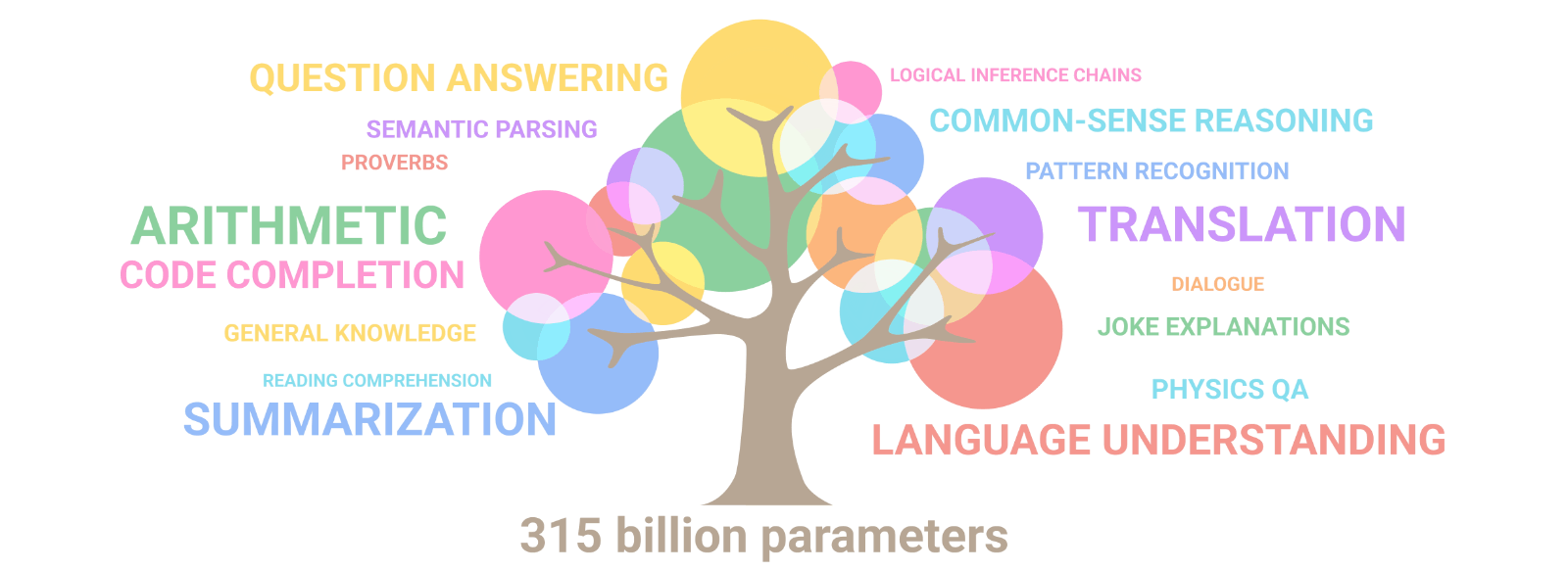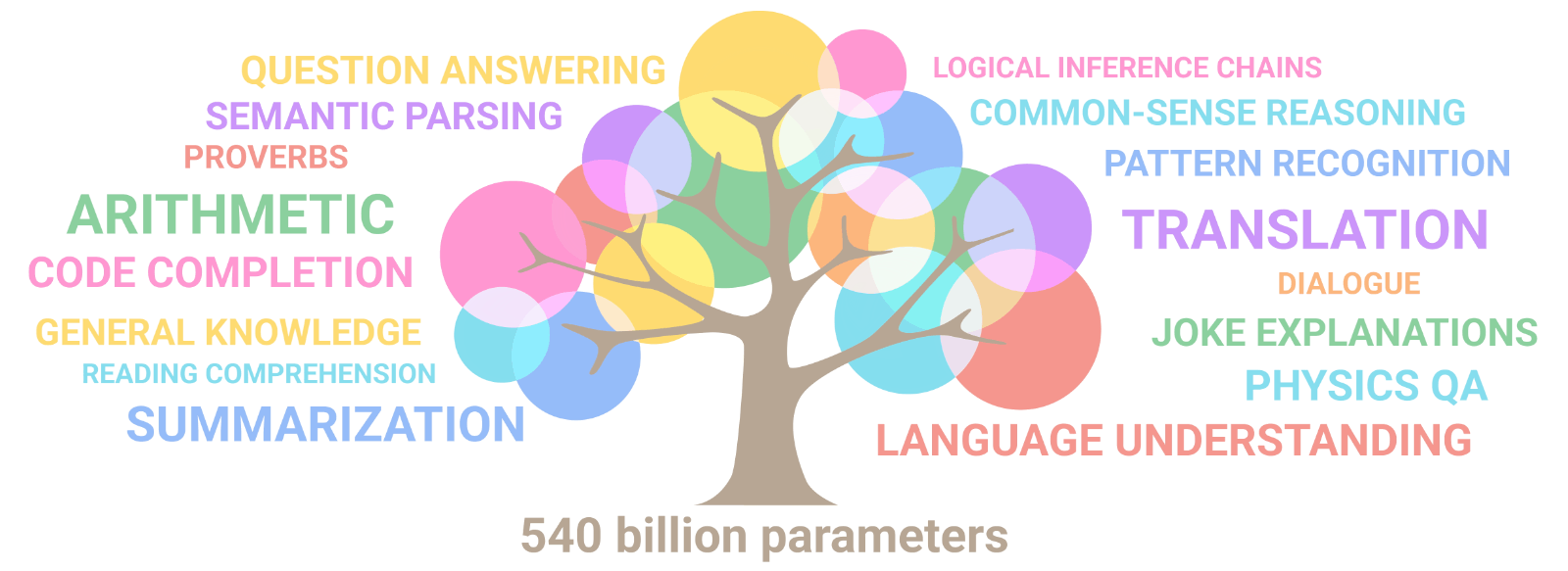
In 2019, the first protein language models appeared (more details in refs 1 and 2). These models learn aspects of proteins such as their subcellular location, folding type, function, etc. “ESM-2,” trained by FaceBook, was the largest protein AI so far, and with it, they predicted the structure of 600 million proteins (ref 3). But that changed just a couple of weeks ago.
The Chinese company BioMap has presented its AI called “xTrimoPGLM,” which is ~7 times larger than the FaceBook AI. Additionally, xTrimoPGLM is the first AI of its kind in the world of proteins, as it is as large as other famous text AIs such as GPT-3. When compared to other AIs, xTrimoPGLM has achieved better performance in multiple predictive tasks related to protein properties and is also capable of generating sequences. It is expected that new strategies will derive from this AI in the following years; however, it is not yet certain that BioMap will make this model “open source,” and we will have to wait a little longer.
Fun fact: xTrimoPGLM’s training began on January 18th and “ended” on June 30th. The preprint was published on July 14th. This means that the Chinese team took 14 days to do all the analyses presented ggg
Refs: