
Post 31: How many sequences do we have so far? 🤔
Published:
Well, no one knows for sure.
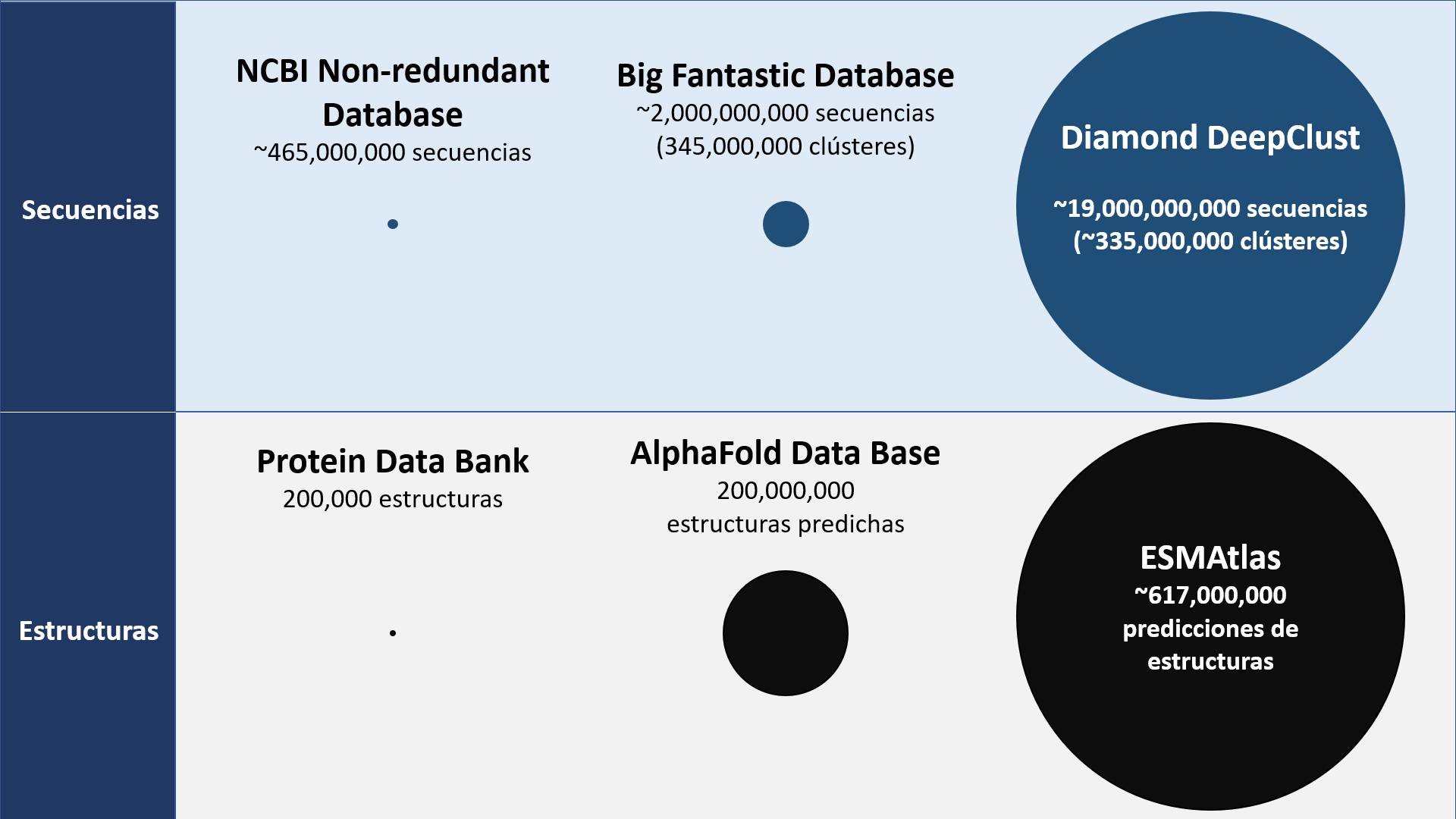
There are many genomic repositories, each with proteins from different environments and species. One of the most famous repositories is NCBI-nr, which is usually used when we do a BLAST; this repository has ~465 million sequences.
But, is it the largest? Not at all. As far as I know, the largest repository so far is called DeepClust and contains ~19 billion sequences, which can be grouped into ~335 million representative sequences (clusters).
And what about protein structures? The Protein Data Bank has ~200,000 structures resolved with different methods (X-ray, Cryo-EM, etc.), but thanks to artificial intelligence that predicts protein structures from the sequence, such as AlphaFold2 or ESMFold, the largest repository with information on structures is now ESM-Atlas, with about 617 million structural predictions, weighing about 15TB of storage.
So now there’s plenty of data… 🤯
Refs:
- Interesting pages:
- The DeepClust paper